Everything looks fine. Until a user tries it.
Three ways your MCP app experiences conversational failures.
36%of failures
You tested your words, not theirs
You wrote 10 prompts that work. Your users try a thousand that don’t. Every person describes your app differently, and you’re not testing any of them.
68%of failures
A local inspector is not ChatGPT
Your users are running on different models, different devices, and you have no idea what’s actually happening.
14%of prompts skipped
Your app simply doesn’t invoke
For your target prompts, the model just skips you. This is critical to your distribution. You need to understand why and fast.
How it works
Uptime monitoring for the AI layer. Four steps.
Claim Your App
Tell us which ChatGPT app to monitor. Setup takes 2 minutes.
Add your golden prompt set
Define the real prompts that matter most for your users and core flows.
We Test Daily
Real ChatGPT browser sessions run against your app every night. Test multiple ChatGPT models (GPT-5.1, instant, mini).
You Know Instantly
Green means working. Red means broken. Screenshot proof. Email alerts on failure.
Whether you ship solo or across a large product organization, the goal is the same: keep your ChatGPT app working reliably.
Builders
For developers and engineers shipping ChatGPT apps who need confidence their integrations work before users hit problems.
Business
For enterprise teams and product organizations that need reliable, repeatable app performance across workflows.
Screenshot proof. Every test run.
Every check captures exactly what ChatGPT did with your app. See the prompt, the response, and whether your app was invoked. No guessing.
Real test result: ALL Accor — “Show me available hotels in Paris for tonight”
- Full screenshot of ChatGPT response
- Invocation status and parameters sent
- Historical pass/fail trends over time
- Email alerts on failure
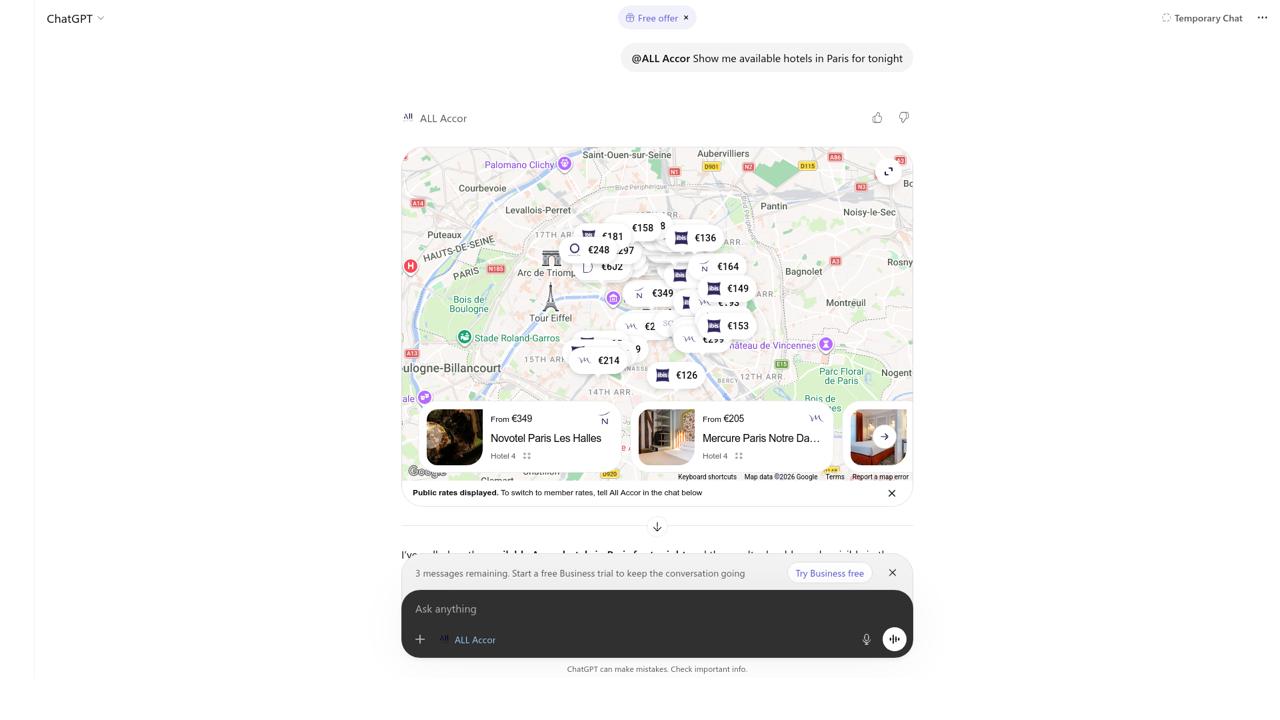
Prompt
“Show me available hotels in Paris for tonight”
Result
App invoked ✓ · Action completed ✓
OpenAI is already scoring your app.
After every tool call, ChatGPT shows users a thumbs up/down. That feedback feeds directly into OpenAI's ranking signals. Every silent failure, every broken invocation, every thumbs down is being recorded.
Failed interactions don't just cost you one user. They actively push your app down in future recommendations. Without monitoring, you're losing ground and you don't even know it.
The AI Discoverability Stack
This is how to get your app discovered by humans and agents.
Dynamic discovery is when AI naturally chooses your app in alignment with the user's intent. Our platform gives you data and agents to improve performance, increase discoverability, and win more users in your category.

Frequently asked questions
Practical details on setup, testing, and alerts.
What does ChatGPT app monitoring actually test?
Each run checks realistic prompts in live ChatGPT sessions, validates whether your app is discovered and invoked, and captures screenshot evidence for every result.
How often does monitoring run?
Monitoring runs nightly by default, with every run recorded so you can track pass/fail trends over time.
What counts as a failure?
A failure is any test where your app is not surfaced when expected, fails to invoke correctly, or returns a broken or incomplete outcome for the target prompt.
Do I need to change my app to use this?
No product rewrite is required. You configure your app and golden prompts, then monitoring runs against real conversations without changing your runtime architecture.
What's a golden prompt set?
It is the prompt set that defines your highest-value user outcomes. These prompts become the baseline scenarios we test continuously.
How do I get alerted when something breaks?
You can configure email alerts daily or on failure, so you always know when something breaks. Alerts include context and screenshot evidence so you can act immediately.
Is my app data kept private?
Monitoring data is scoped to your account and used for test execution and reporting. Prompt and result history is retained for debugging and trend visibility.
What's the difference between discovery failure and invocation failure?
Discovery failure means your app is not selected when it should be. Invocation failure means ChatGPT selects your app but the action fails or returns a broken result.